


Introduction
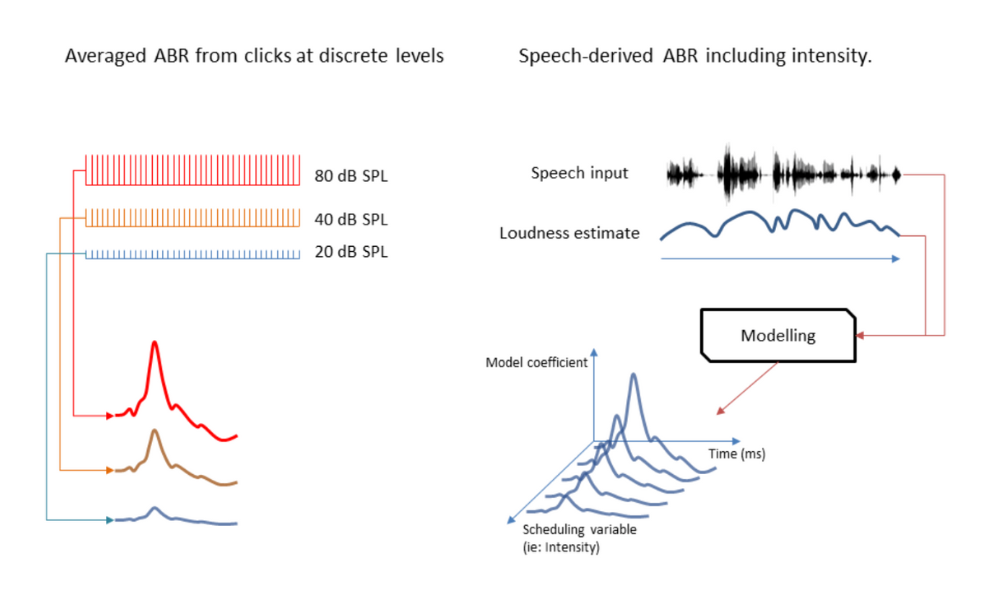
Auditory brainstem responses (ABRs) are typically obtained by averaging EEG reactions to repeated transient stimuli, allowing the characterization of the link between stimulus strength and ABR peak amplitude and latency. This makes ABRs a valuable objective tool for hearing assessment. Recent advances have revealed that EEG responses, like ABRs, can be extracted from continuous speech stimuli, achieved through linear modeling with the speech stimulus as a predictor and EEG as the dependent variable. Yet, little is understood about how speech-derived brainstem responses change with stimulus intensity or how different modeling approaches affect the non-linear response patterns.
This project is supported by the William Demant Foundation.
Aims
Signals similar to ABRs can be extracted from EEG recorded during continuous speech listening. However, these signals, called temporal response functions (TRFs), are time-varying impulse responses resulting from a linear model without explicit intensity consideration. This project aims to enhance these methods, incorporating calibrated stimulus intensity measures. The goal is to create models producing diverse TRFs for varying intensity levels while preserving original output amplitudes. These optimized TRFs could be invaluable in hearing assessment and threshold estimation with any stimuli. The project’s outcome will provide a set of methods optimized for generating intensity -dependent TRFs from continuous speech stimuli.
Methodology
We’re using our knowledge of non-linear systems to characterize the relationship between stimulus intensity and speech-derived brainstem responses. By testing different methods, we aim to design a model that takes stimulus intensity into account. Our goal is to create a model that changes with the loudness of the speech. This model can serve a similar purpose to averaged ABRs at several stimulus levels, but it’s derived from continuous speech stimuli, offering advantages over repeated discrete clicks.

